How Trail Router works
Published 2020-06-03
Trail Router is a running route planner with a difference. Its routing algorithm favours greenery and nature, and biases against busy roads. It also allows you to create 'round-trip' routes of a desired distance, as well as the more traditional point-to-point routes.
This blog post is about the creation of Trail Router and how it works under the hood.
Motivation
I began writing Trail Router in the summer of 2019. At the time, I was travelling regularly for work to cities I'd never been before in Australia, New Zealand, the US, Europe and beyond. I always go for runs in the new places I visit - it's a great way to see a new location and it helps with the jetlag. But not knowing these locations, I didn't know where was good to run and where was not.
And so I was finding myself up at 4am, jetlagged, on GMap Pedometer plotting a route and then checking out its suitability using Google Street View. I could have just as easily have been using MapMyRun, Strava's Route Builder or a bunch of others. But they all required firing up my laptop, manually drawing a route and then verifying that it was actually nice to run on. Even Strava's heatmap, as great as it is, cannot be used a proxy for how nice a route is, as it's often dominated by commuters in cities. This all seemed like a lot of effort when I was just planning on running 5-10km!
Ultimately I wanted a simple web or mobile app that would suggest round-trip routes (starting and ending at my current location), met some rough distance that I specified, and took in some nice scenery (e.g. parks, rivers, forests).
I searched for something that fit the bill, but nothing did. This seeded the idea for Trail Router!
Objectives
My objectives for Trail Router could be summarised as follows, in rough order of priority:
- Automatically suggest round-trip routes that meet a specified target distance
- Favour greenery and other natural features in routes, and avoid busy roads where possible
- Avoid repetition ('out-and-backs') in the route suggestions
- Allow users to easily edit any of the route suggestions
- Be designed for use on mobile devices
- Require minimal user input - ideally no clicks at all!
- Be available globally, partly for the benefit of other users, and partly for me (because I don't know where I will travel to)
- Require no login and be as privacy friendly as possible
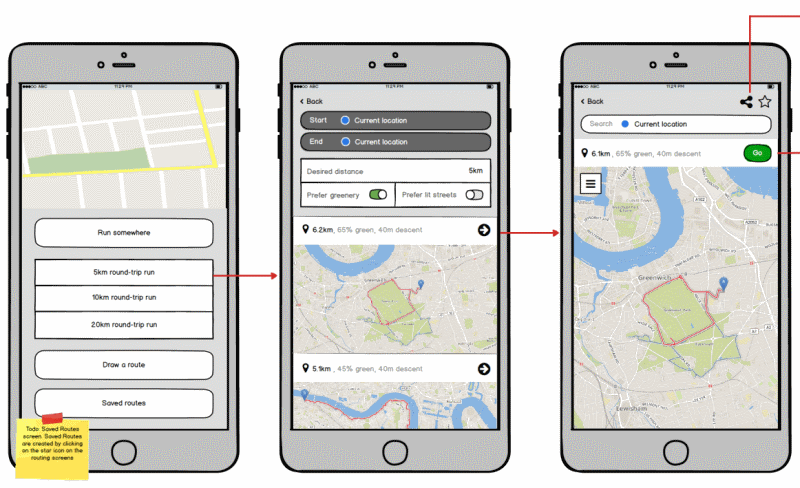 An early mockup of the user interface, heavily inspired by CityMapper. The current user interface looks quite different.
An early mockup of the user interface, heavily inspired by CityMapper. The current user interface looks quite different.
Selecting a development stack
Routing engine
After one look at the routing API documentation from the major mapping providers (e.g. Google, Mapbox), it became clear to me that I could not use their APIs to build Trail Router. They lacked any concept of round-trip routing or preferring greenery.
The open source routing engines looked much more promising. I soon discovered GraphHopper and Openrouteservice (which is based upon GraphHopper and adds more functionality). Both offered cloud-hosted APIs and open source versions that you could host yourself. Unfortunately the cloud-hosted APIs from both were insufficient:
- GraphHopper offers round-trip routing, but I discovered through experimentation and reading the code that its approach is too naive for my use case. It creates a route by effectively drawing a circle that starts and finishes at your current location, plotting a few waypoints around the circumference of that circle, and then routing between these waypoints. It is unaware of any green features nearby (e.g. parks, forests, rivers, lakes), so will not prefer them in its route suggestions.
- Openrouteservice allows users to set a 'green preference'. This feature is only available in Germany though. This meant I would need to use the self-hosted open source version and generate my own greenery data if I wanted to use Openrouteservice.
This meant I'd have to pick one, extend it to meet my needs, and then self-host my own instance.
Map data
Both GraphHopper and Openrouteservice use map data from OpenStreetMap. Exploring my local area with OpenStreetMap, I discovered it contained structured data describing roads/paths (called "ways" in OpenStreetMap), parks, bodies of water, and even hiking routes. The 'tags' associated with each object were the key thing though - these described whether the 'ways' were footpaths or motorways, or whether this big polygon was a park. For example, look at the tag data associated with Greenwich Park in London. This structured data was available in a variety of formats and could even be imported into a database using osm2pgsql.
Final stack
The stack I ended up settling on was:
- Openrouteservice for the routing engine (with significant modifications), self-hosted.
- OpenStreetMap for source map data (currently ~55GiB for the whole planet).
- PostgreSQL with the PostGIS plugin for running SQL queries over the OpenStreetMap data (sometimes in precomputation, sometimes at runtime. More on that below).
- Leaflet and leaflet-routing-machine (with significant modifications) for the frontend web app.
- A large dedicated server to run all of this on. See the infrastructure section near the end of this post.
- Mapbox for my base layer maps and overlays.
Whilst I based my development on top of Openrouteservice, I will make frequent reference to GraphHopper in the remainder of this post. This is because Openrouteservice is itself built on top of GraphHopper, and lots of the functionality I use is provided directly by GraphHopper. Sorry for any confusion.
This blog post focuses very heavily on the backend. If there is interest, I will happily write another post describing the frontend and mobile app work.
Point-to-point routing
Point-to-point routing is the standard type of routing the you're used to when using Google Maps or similar. It gets you from A to B. Of course, you can have A to B to C, but that's really just two routes joined together (we call these segments).
All routing engines rely on a path finding algorithm under the hood, and A* is probably the most common. A* effectively tries to find the path between A and B with the minimal 'cost'. The 'cost' is most commonly distance (i.e. you want to find the shortest route), but there are many others. For example, the shortest route may not be the fastest, given speed limits and traffic conditions.
GraphHopper's routing algorithm supports 'shortest' and 'fastest' weightings out of the box (and many more). Crucially, it also provides a way for you to extend these weightings too.
There's a couple of ways to do this, and Trail Router uses both.
Flag encoders
GraphHopper has different 'vehicle profiles' for each mode of transport - e.g. foot, car, bicycle, and many more. Each one of these vehicle profiles has different rules. For example, the 'foot' and 'bicycle' profile should not allow motorways / interstates to be used, but it's fine for the 'car' profile to use.
Flag encoders are where these rules are defined. The FootFlagEncoder from OpenRouteService is a fairly readable example of this. There's a lot of code in here, but fundamentally it works as follows:
- When GraphHopper starts up for the first time (before its graphs have been generated), it will parse the OpenStreetMap file and call
handleWayTagsfor every OSM (OpenStreetMap) way. handleWayTagscan either (a) return a result indicating that this way cannot be used for this vehicle profile, or (b) return a resulting indicating that this way can be used and its priority.- GraphHopper writes the resulting data out to a file in an optimised binary format. On each subsequent start, it just reloads these files rather than parsing the source data again.
Trail Router creates a new flag encoder that tweaks the FootFlagEncoder rules slightly. These rules do not give us anything in terms of 'green routing' yet, but they set the basics for what ways we want to be allowed/disallowed, and whether any should be prioritised over others. In summary, this does the following:
- Prefers dedicated footpaths, bridleways and hiking routes.
- Prefers roads with low speed limits.
- Only uses primary, secondary and tertiary roads as a last resort, unless they have a sidewalk.
- Will never use any trunk roads unless they have a sidewalk.
- Will never use a primary or secondary road with a bridge or tunnel unless it has a sidewalk for that section.
Green routing
Openrouteservice already provides a 'green weighting', which looked like it would suit my needs quite well. Unlike the Flag Encoders, it relies on more than just parsing the OpenStreetMap files. It relies upon an external CSV file that contains a mapping from each OSM Way ID to an index of how 'green' that way is. Openrouteservice already provided the tools to read this CSV file, store the resulting data in a GraphHopper graph storage file, and then use that data to apply a weighting at runtime (giving a higher preference to ways with a higher green index).
However, the good news ended there: Openrouteservice does not publish the code for calculating this green index, and their publicly available instance only supports Germany. So we will need to recreate it!
The basic idea is this: Create a 30 metre buffer around each way, and calculate the intersection between that buffered way and any green features nearby. I am using 'green features' to refer to polygons in OpenStreetMap's database, such as a park. The fraction of the buffered way that lies within green features is our green index for that way. For example, this way is completely enclosed by the park so its green index would be 1. But this road, which runs next to a park for a short distance, only has a green score of 0.26.
Calculating the green index for all ways on the planet would require a huge amount of processing. There are 668 million ways in the OpenStreetMap database as of May 2020, and I'd be asking to compare every 'line' way against every 'polygon' way. This would be billions of comparisons, which sounded like a job for a database. I had heard of PostGIS, the geospatial plugin for PostgreSQL, and its documentation suggested that it would be well suited to this task.
The rough process was as follows:
- Install Postgres and PostGIS
- Import the OpenStreetMap planet dataset using osm2pgsql (takes ~1 day)
- Run an SQL query that looked something like the following and save the output as a CSV (takes ~2 days):
SELECT
l.osm_id,
sum(
st_area(st_intersection(ST_Buffer(l.way, 30), p.way))
/
st_area(ST_Buffer(l.way, 30))
) as green_fraction
FROM planet_osm_line AS l
INNER JOIN planet_osm_polygon AS p ON ST_Intersects(l.way, ST_Buffer(p.way,30))
WHERE p.natural in ('water', ...) or p.landuse in ('forest', ...) or ...
GROUP BY l.osm_id
Once the CSV was generated, I plugged it into Openrouteservice's existing green weighting functionality and was now generating point-to-point routes that favoured greenery over busy roads! At this point I could now generate routes that looked like this:
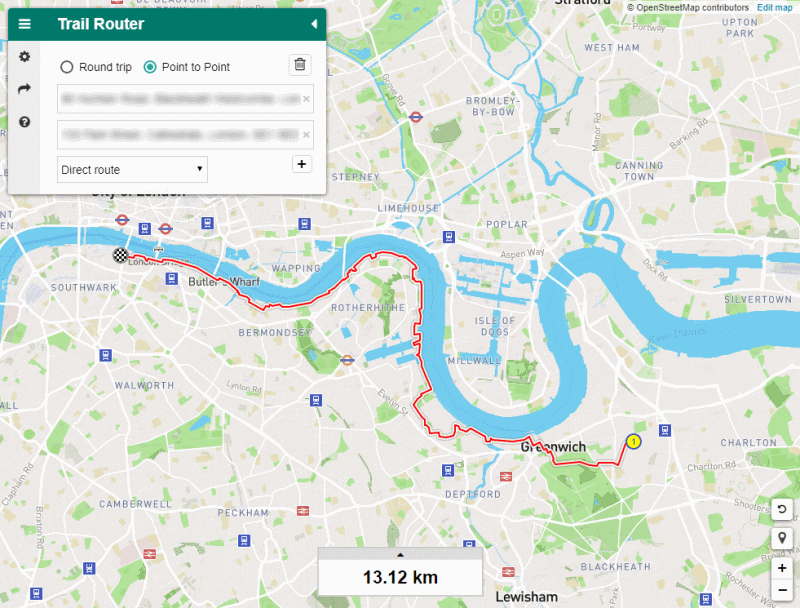 The route that Trail Router suggests between Greenwich and central London, with green routing enabled. You can see that it hugs the River Thames and takes in other greenery where possible, at the expense of distance.
The route that Trail Router suggests between Greenwich and central London, with green routing enabled. You can see that it hugs the River Thames and takes in other greenery where possible, at the expense of distance.
Of course, whilst the above steps seem relatively simple in hindsight, it took weeks of trial-and-error in the evenings to get this working.
Avoiding repetition
Before we move on to talk about round-trip routing, I wanted to mention one other type of weighting that would be important for round-trip routing. One thing many runners are keen to avoid is out-and-back routes - i.e. run 5 miles along the beach, turn around and then run 5 miles straight back. None of the existing tools out there had anything like this.
The basic idea was this: If our algorithm attempts route over the same edge twice, then the second time we see it we want to apply a big penalty to it (to steer us away from it).
Unlike with the FootFlagEncoder and Green Routing, it was not possible to pre-calculate weights for avoiding repetition, as it is entirely dynamic. However, there was one key realisation that made this feature possible: a route that would involve repetition is made up of multiple segments (for example: one segment goes east along the beach, and then next segment goes west back to the start). This meant that I could use the results from earlier segments to influence later ones.
The approach taken was as follows:
- Whenever a segment of a route is completed, collect all edge IDs traversed in that segment add them to a 'visited edges' hash set. (Note: GraphHopper splits OSM ways up into edges, each of which has an ID)
- On the next segment, when calculating the weight for an edge, check to see whether its edge ID is in the visited edges hash set. If so, return a large penalty for selecting this edge.
This approach works quite well, but it has obvious flaws. It uses an exact comparison between edge IDs to determine repetition. So if there's two paths parallel to one another on our hypothetical beach, the algorithm will happily send you up one path, and back down the other. This probably isn't what users would want, so future work in this area will look at avoiding edges based upon proximity rather than edge IDs alone.
Round-trip routing
Round-trip routes are those that start and finish at the same location. I wanted Trail Router to automatically suggest round-trip routes that met a user-specified distance (approximately). These routes should also factor in greenery and other natural features nearby.
Naive approach
The naive approach was similar to GraphHopper's:
- On an initial heading of 0 degrees, draw a circle with a circumference of the user's desired route distance.
- Pick three evenly spaced points on the circumference of the circle, and find the nearest OpenStreetMap ways to each of those points.
- Plot a 'green' route between the points.
- This is our suggested round-trip route for the 0 degrees heading. Add it to the route list.
- Repeat steps 1-4 in 45 degree heading increments.
- Filter out routes from the list that are <50% or >200% of our desired distance.
I refer to this as a 'naive' approach because the point selection is really just picking points and hoping for the best. This works quite well on large round-routes (typically 20km+), but it's very poor on short routes. The key reason is that it doesn't take into account any green / natural features nearby. For example, if you live near a park and it's big enough, you would probably expect that this park would be used in your routes. The naive approach does not do this though (see the picture below).
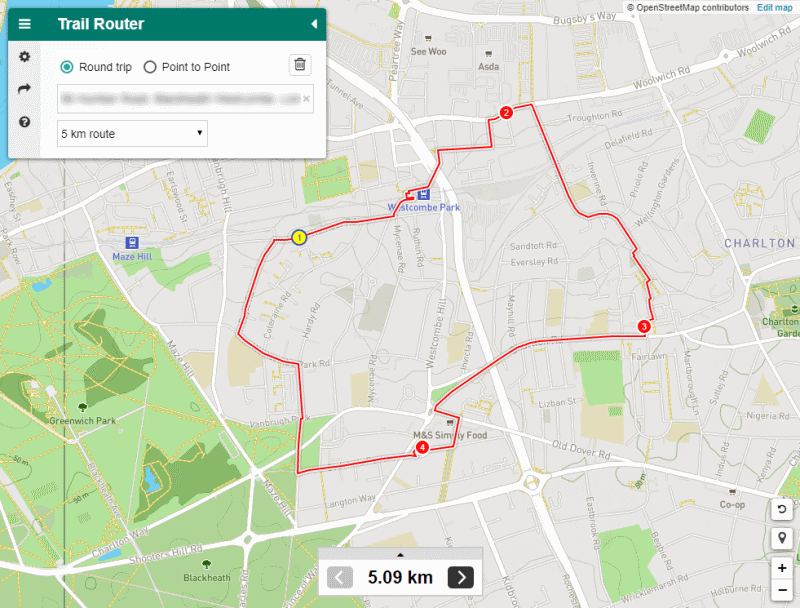 A 5km round-trip route suggested using the naive approach. You can see that it's chosen three waypoints and routed between them. It's come up with a distance close to our desired 5km, but completely ignores Greenwich Park to the west.
A 5km round-trip route suggested using the naive approach. You can see that it's chosen three waypoints and routed between them. It's come up with a distance close to our desired 5km, but completely ignores Greenwich Park to the west.
Improved approach
The results from the naive approach demonstrated clearly to me that something better had to be based upon the green features near to the user. The OpenStreetMap database once again became useful here, as it contains exactly the features we want. I decided to base my improved round-trip routing on the following map features:
- Green spaces - e.g. forests, parks, meadows.
- Water - e.g. coastlines, rivers, lakes.
- Hiking routes (based upon 'relations' with route=hiking and similar tags in the OpenStreetMap database).
The approach I decided to take involved searching for any of the above features near to the user's requested start location, plotting points along the perimeter of it (as a hint to the routing algorithm) and then plotting a final point back at the start to complete the round trip. The resulting set of points is referred to as a 'candidate route'. I've glossed over lots of details here (such as merging adjacent features, ensuring that the feature has routable paths inside it, trying multiple directions, and more).
This was implemented as a very large stored procedure in Postgres. The procedure accepted a lat/lng and target distance as input, and returned an array of candidates (points around the perimeter of a feature). The Java application calls this stored procedure whenever a user requests a route, and then it tries to create a route using each candidate. If a route cannot be calculated or it's far longer than the user requested, then it isn't shown to the user.
Each remaining route is then scored using a combination of (a) how green it is and (b) how closely it matched the user's target distance. The combined score determines the ordering of the routes that are displayed to the user.
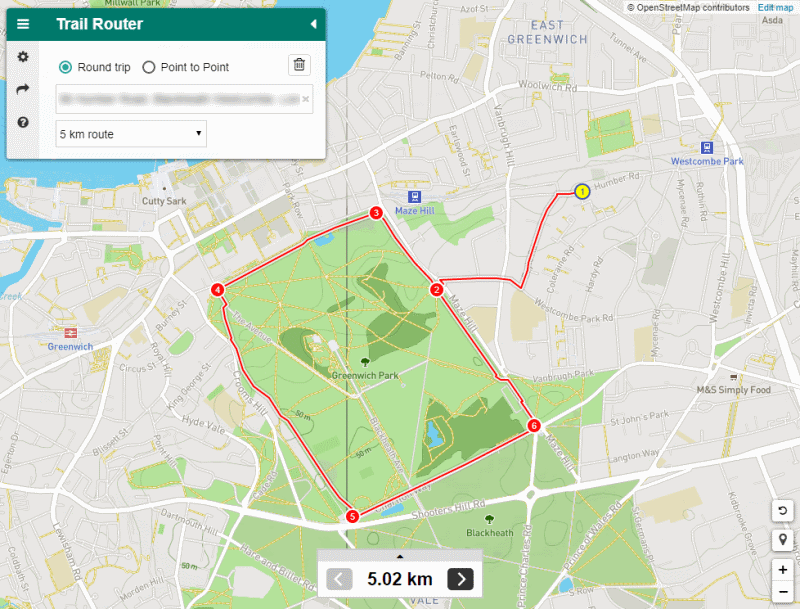 The 5km round-trip route suggested from the same location as before. You can see that the improved approach takes into account the presence of Greenwich Park and routes around it.
The 5km round-trip route suggested from the same location as before. You can see that the improved approach takes into account the presence of Greenwich Park and routes around it.
Infrastructure
Trail Router runs its own routing engine and stores the whole planet's data. Unsurprisingly, this requires quite a lot of resources. At the moment we have the following infrastructure:
- Server 1: 2x E5-2690v2, 256GB RAM, 2x 1TB SSD
- Server 2: E5-1650v3, 256GB RAM, 1.92TB SSD
- Server 3 (dev): 4GB Linode
Server 1 and Server 2 alternate in their roles: Whilst one is reprocessing the planet's data (which takes around 5 days for all of the graph and index precalculation), the other is serving production traffic. The development server has just enough resources to store the England OSM dataset.
A large amount of RAM is required due to the osm2pgsql imports and the pre-calculation phase in Openrouteservice. I have experimented with lowering the RAM to 128GB successfully, but it peaks at 120GB during pre-processing. With the OpenStreetMap database growing every day we would likely exhaust 128GB before too long.
The two large servers are dedicated servers hosted with Hetzner in Germany and Tier.net in Texas. Both cost around $110/month. I dread to think how much more expensive it would be with AWS or GCP. Dedicated servers and colocation certainly still has its merits for some use cases.
Conclusion
I started developing Trail Router out of frustration with existing route planning tools. They would often route pedestrians along busy roads when much nicer alternatives were available, and they didn't support features like round-trip routing.
That frustration soon transformed into curiosity though. I'd never previously worked on a GIS project, and I was astounded by the availability of data (OpenStreetMap) and tooling (Openrouteservice, GraphHopper, PostGIS, etc). I was excited to see what I could make!
I'm pleased that Trail Router has met all of the original objectives I set, but there's still features to add and usability issues to refine. The feedback from the running community has been very positive. Some coverage can be found here, here and here. Around 3,000 routes are being created on an average day, and this can spike 10x when a post mentioning it becomes popular.
I look forward to the coronvirus lockdown ending so I can travel to new places and try Trail Router in a new location for myself!
Many thanks to Daniel Westergren for reviewing an early draft of this post.